
Reference: This article should be read alongside our Scheduling data updates article, where we cover many more important concepts and decisions about scheduling updates to data.
We have prepared a series of guides for data publishers that provide a step-by-step technical walkthrough of scheduling updates to your data through data.wa.gov.au’s Data Upload Tool.
Each guide covers:
- Preparing your data for ingest through DUT
- The software requirements for uploading data
- Step-by-step instructions detailing how to perform an upload
- Guidance about scheduling uploads to automate the process of uploading data
Introduction
The purpose of this document is to provide GIS developers a step by step guide how to integrate Python code and the Esri arcpy library to automate Data Upload Tool data updates.
The target audience for this document are Python GIS developers. For the non-developers Landgate has also documented automatic updates of data in Data Upload Tool using FME or using the AWS command Line Interface.
Requirements
- The Esri arcpy Python module is required for both data exporting slips (1.3.1 and 1.3.2). This is automatically installed with ArcMap.
- A dataset must already have been loaded into the Data Upload Tool and the application approved.
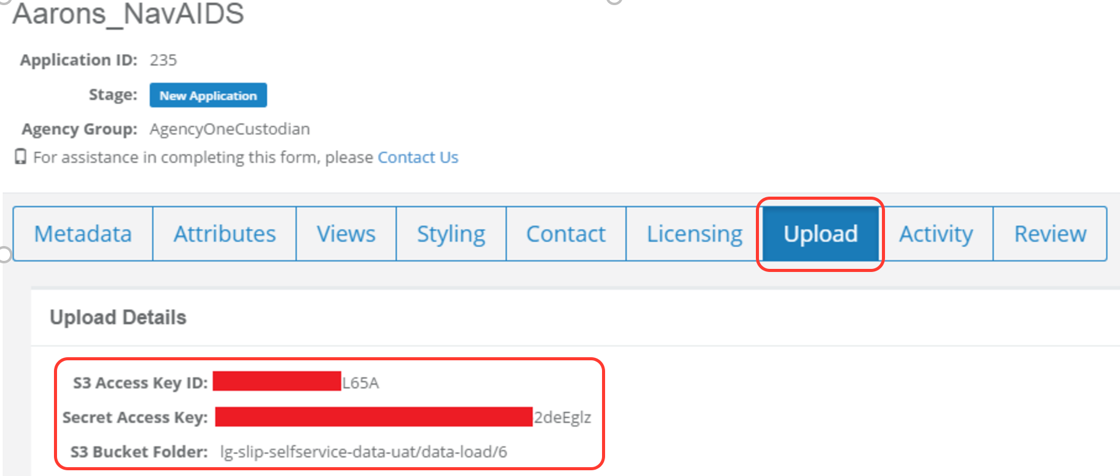
- Have access to your Data Upload Tool AWS S3 access ID, secret key and bucket details. These details can be found under the Data Upload Tool upload tab as shown below:
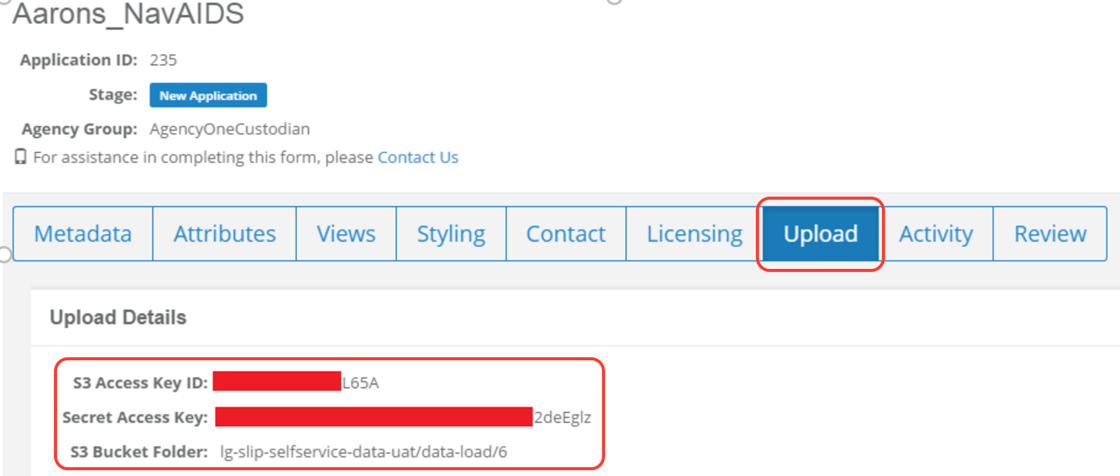
All scripts have been developed to run using Python 2.7.x (https://www.python.org/).
Code Snippets
This section includes code snippets to perform the following processes:
- Exporting a SDE layer to a Shapefile (Section 1.3.1).
- Exporting a SDE layer to a Esri file geodatabase (Section 1.3.2).
- Zipping a shapefile (Section 1.3.3).
- Zipping a Esri file geodatabase (Section 1.3.4).
- Uploading to AWS S3 Data Upload Tool bucket (Section 1.3.5 – 1.3.6 -1.3.7).
Section 1.4 provides an example how to bundle all the snippets into a complete workflow script that will export your data from SDE to fileGeodatabase, compress the fileGeodatabase and finally upload the zipped file to the Data Upload Tool.
Exporting a SDE layer to Shapefile (Windows Only)
Note: It is important that the exported shapefile filename and the schema matches the original dataset registered in the Data Upload Tool.
Before exporting your data to shapefile, be aware that the shapefiles format has the following limitations:
- Each component of a shp file (ie *.shp,*.shx,*.dbf) cannot exceed 2GB each.
- Field names are limited to 10 characters in size and Unicode characters are not allowed (ie * / % $ etc.).
- Shapefiles cannot store NULL values, this can cause issues with some queries.
- XYZ precision of is lower than fileGDB and therefore rounding can occur.
- Maximum text field is 254 characters. Larger fields will be truncated.
If any of the above limitations are likely to cause issues with your data, consider exporting your data to Esri filegeodatabase (Section 1.3.2).
Use the Python code below to create a function called sde2shp.
https://github.com/datawagovau/fme-workbenches/blob/master/upload-geospatial-data/python/sde2shp.py
To execute the sde2shp function pass the following four user definable parameters:
- SDE_Connection: Esri documentation to create a SDE connection.
- Name of input: SDE Featureclass to be exported to shapefile.
- Output path: where to store the exported shapefile.
- Shapefile output name: the name of the output shapefile must be the same as the name of the shapefile used to register the dataset.
For example:
OutputSHPFilePath = sde2shp(r'C:\AARON_DATA\Connection_to_PEAS71-DISS- SDE.sde','GDB.W_IMAGERY_METADATA',r'C:\AARON_DATA','LGATE071.shp')
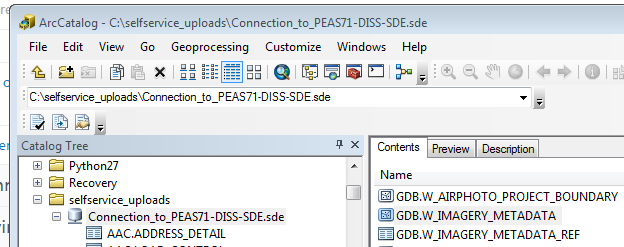
Executing this function will export the feature class GDB.W_IMAGERY_MEATADATA to a shapefile LGATE971.shp.
The function will also return the path to the shapefile. In this example the value of the OutputSHPFilePath variable will be c:\AARON_DATA\LGATE071.shp.
Exporting a SDE Feature layer to ESRI File geodatabase (Windows Only)
The Data Upload Tool also supports the Esri file Geodatabase format.
Note: It is important that the exported feature class name and the schema matches the original dataset registered in the Data Upload Tool.
Domain tables and subtypes are not currently supported. If domains do exist, only the domain codes will be ingested into the Data Upload Tool. It is recommended to flatten the domain field during data export stage.
Another known issue is that the current version of Data Upload Tool only handles geodatabases created from ArcMap10.3.1 or earlier. A workaround for users using a later version of arcmap is by defining an early version of the output fileGeodatabase using the create geodatabase tool.
Use the Python code below to create a function called sde2fgdb:
https://github.com/datawagovau/fme-workbenches/blob/master/upload-geospatial-data/python/sde2fgdb.py
To execute the sde2fgdb function pass the following four user definable parameters:
- SDE_Connection: ESRI documentation to create a SDE connection.
- Name of input: SDE Featureclass to be exported to shapefile.
- Output path: where to store the exported shapefile.
- Name of the exported Shapefile: the name of the output shapefile should be the same as the name of the shapefile used to register the Data Upload Tool dataset.
For example:
PathtoFGDB = sde2fgdb(r'C:\AARON_DATA\Connection to PEAS71 - DISS - SDE.sde','GDB.W_IMAGERY_METADATA',r'C:\AARON_DATA','LGATE071','LGATE071')
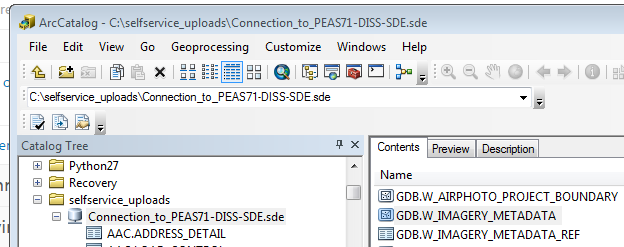
Executing this function will export feature class GDB.W_IMAGERY_MEATADATA to a feature class named LGATE071 and store it in File Geodatabase named LGATE071.GDB.
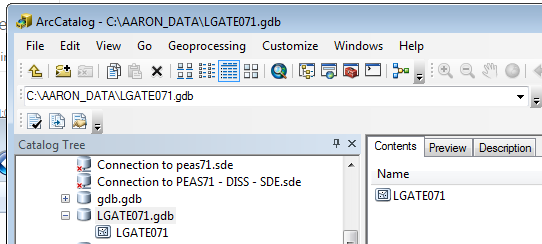
The function will also return the path of the file Geodatabase. In this example the value of the PathtoFGDB variable will be c:\AARON_DATA\LGATE071.GDB.
Zipping up a shapefile
Before uploading a shapefile into Data Upload Tool the dataset needs to be compressed into a single zip file. The zip file should only contain a single shapefile.
Use the Python code below to create a function called ZipShp.
https://github.com/datawagovau/fme-workbenches/blob/master/upload-geospatial-data/python/shp2zip.py
To execute the ZipShp function pass the following two user definable parameters:
- Path to the Shapefile to compress.
- True/False Delete the uncompressed version of the shapefile.
For example:
locationOfZipfile= ZipShp(r'D:\selfservice\shapefile\DOT_Vavids.shp', False)
Executing this function will create a zip file DOT_Valids.zip that contains all the file components of the DOT_Valids shapefile.
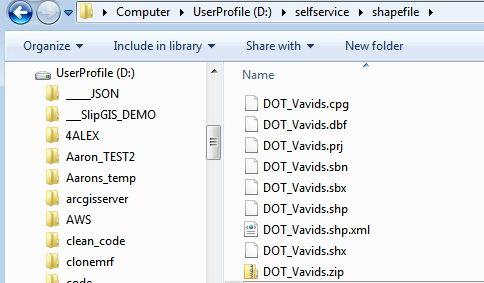
The function will also return the path of the zipfile. In this example the value of the locationOfZipfile variable will be D:\selfservice\shapefile\DOT_Vavid.zip.
Zipping a ESRI FileGeodatabase
The Data Upload Tool also accepts filegeodatabase as an input format.
Note : The geodatabase zip file must only contain the files within the *.gdb folder and not include the folder itself.
Use the Python code below to create a function called Zipfgdb.
https://github.com/datawagovau/fme-workbenches/blob/master/upload-geospatial-data/python/gdb2shp.py
To execute the Zipfgdb function pass the following two user definable parameters:
- Path to the filegdb to compress.
- True/False Delete the uncompressed version of the filegdb.
For example:
Path2filegdb = Zipfgdb(r'D:\selfservice\filegeodatabase.gdb', False)
Executing this function will create a zip file containing all the files within the filegeodatabase.gdb folder without including the folder itself:
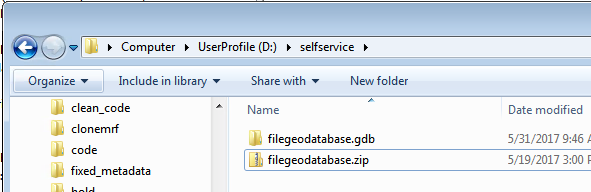
The function will also return the path of the zip file. In this example the value of the Path2filegdb variable will be D:\selfservice\filegeodatabase.zip.
Uploading a AWS S3
The boto3 Python module will enable Python scripts to interact with AWS resources, for example uploading files to S3. Because boto3 isn’t a standard Python module you must manually install this module.
An easy way to install boto3 is by using the Python PIP installer.
Installing PIP
Download get-pip.py to a folder on your computer. Open a command prompt window and navigate to the folder containing get-pip.py. Then run:

This will install pip. Verify a successful pip installation by opening a command prompt window and navigating to your Python installation's script directory (default is C:\Python27\Scripts or C:\python27\Argcis10.3\Scripts). Type pip freeze from this location to launch the Python interpreter. pip freeze displays the version number of all modules installed in your Python non-standard library:
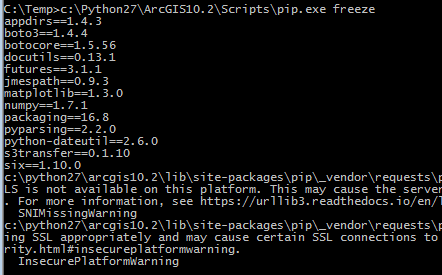
Installing Boto3 using PIP
Type the following to add the boto3 module to your version of Python:

Using AWS Profiles for uploading data to S3
It is best practice not to store AWS credential in your code due to security reasons. The preferred option is to create a folder called .aws in the logged user home directory:
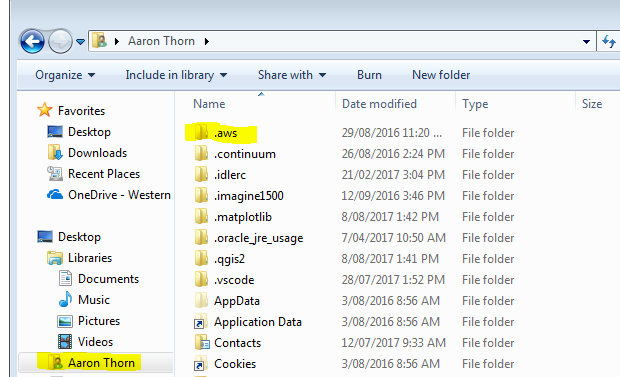
In this folder create two files without file extensions called config and credentials:
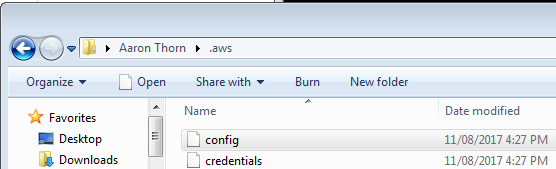
Open the config file in notepad.
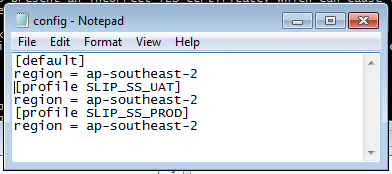
Copy the following text into notepad, save file and close notepad:
[default]
region = ap-southeast-2
[profile SLIP_SS_UAT]
region = ap-southeast-2
[profile SLIP_SS_PROD]
region = ap-southeast-2
Log into the Data Upload Tool.
Navigate to an existing registered dataset and select the upload tab to retrieve the AWS credential details:
Open the credentials file in notepad.
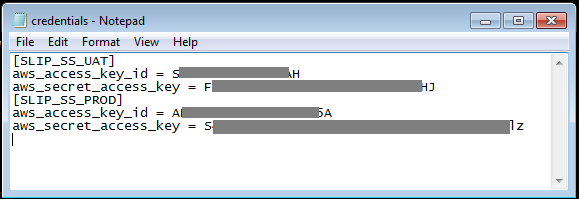
Copy the following text into notepad, enter your PROD&UAT access/secrete key, save file and close file.
[SLIP_SS_UAT]
aws_access_key_id = <enter s3 access key here>
aws_secret_access_key = <enter s3 secrete key here>
[SLIP_SS_PROD]
aws_access_key_id = <enter s3 access key here>
aws_secret_access_key = <enter s3 secrete key here>
Use the Python code below to create a function called UploadFile.
To execute the UploadFile function pass the following four user definable parameters:
- Path to the zip file to upload.
- S3 bucket name.
- S3 bucket key.
- AWS credential profile.
For example:
print UploadFile(r'D:\selfservice\myData2.zip','lg-slip-selfservice-data-uat','data-load/6/s3_upload.zip', 'SLIP_SS_UAT')
Using hard coded AWS credentials for uploading data to s3
In some situations, it may be easier to hardcode the AWS credential into the source code. The code below provides an example how to this can be done.
Entered the relevant KEY, SECRET, BUCKET and BUCKET_KEY parameters into the code.
To execute the UploadFile function pass the file path to the zip file to upload to S3.
For example:
print UploadFile('/Users/AaronThorn/Downloads/LGATE071_asat_2017_08_17.zip')
The function will then return the s3 URL link. (ie https://s3-ap-southeast-2.amazonaws.com/lg-slip-selfservice-data-uat/data-load/6/LGATE071_asat_2017_08_17.zip).
End-to-end example
The following script provides an example how to integrate all the code snippets in section 1.3 to build an end to end script that extract a single feature class from SDE to a fileGDB, zip the fileGDB and finally upload the zip file to S3.
The script requires boto3 to be installed as detailed in section 1.3.5. Also the AWS profile config and credential files must be set up as described in section 1.3.6.
Copy and paste this code in a text editor. Save this file as ESRI_FGDB_2_SLIP.py
To execute the ESRI_FGDB_2_SLIP.py script it is best to use a batch file to configure the following parameters:
- Path to the Python executable.
- Path to fGDB2SelfService.py code.
- Path to the SDE connection file.
- SDE feature class to export.
- Temporary working directory where to store the logfiles and file Geodatabase.
- AWS credential profile name.
- S3 self-sevice bucket (ie lg-slip-selfservice-data-prod or lg-slip-selfservice-data-uat).
- S3 bucket ket (ie data-load/#/).
Use the following as a batch template. Cut and paste the following into notepad and edit the variables as required. Save this file with either a *.cmd or *.bat file extension.
Test the batch file by double clicking the batch file:

A date stamped zipped file and log file will be created each time the batch is executed.
Scheduling
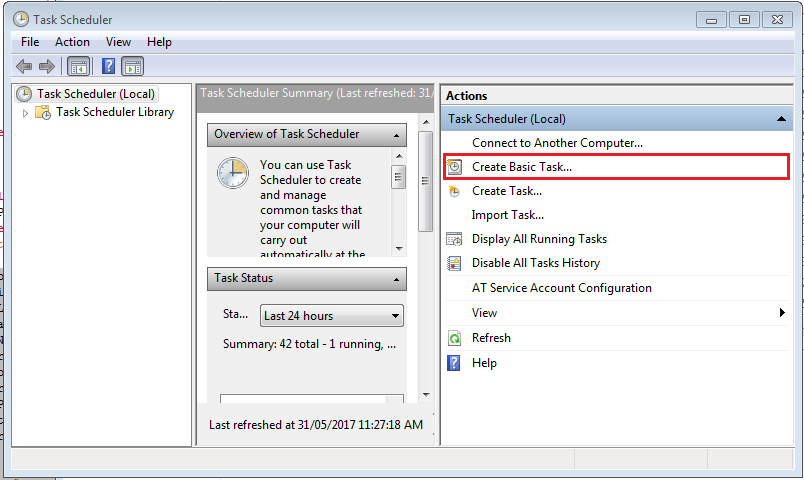
To schedule this job to run at regular intervals open Windows Task Scheduler and select create basic task:
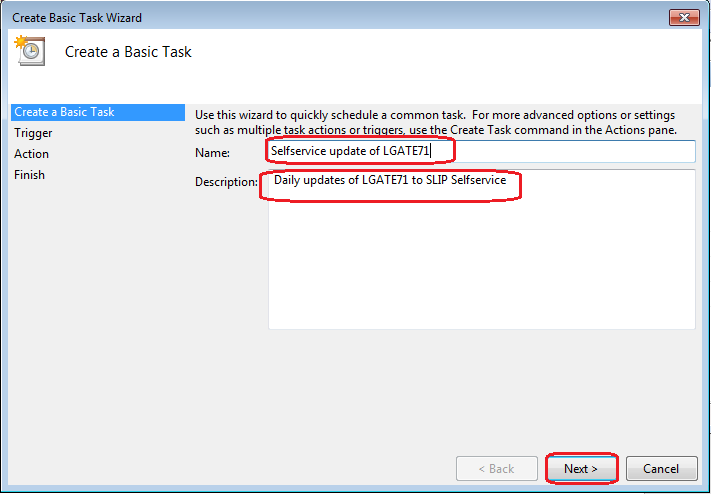
Type in a meaningful task name and description:
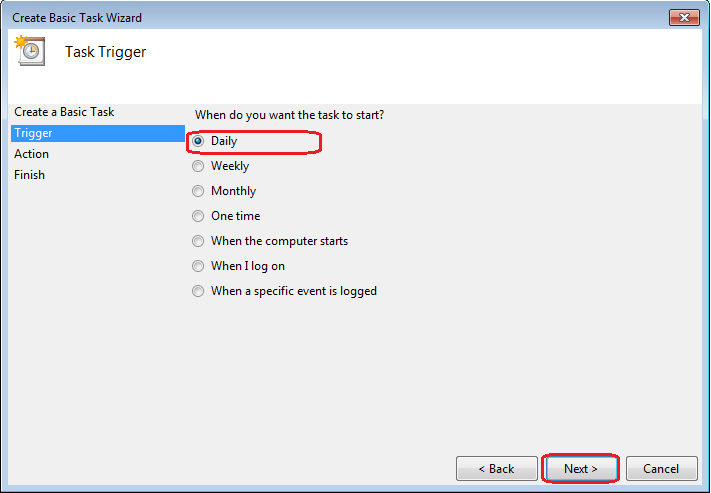
Select how often you want the task to run:
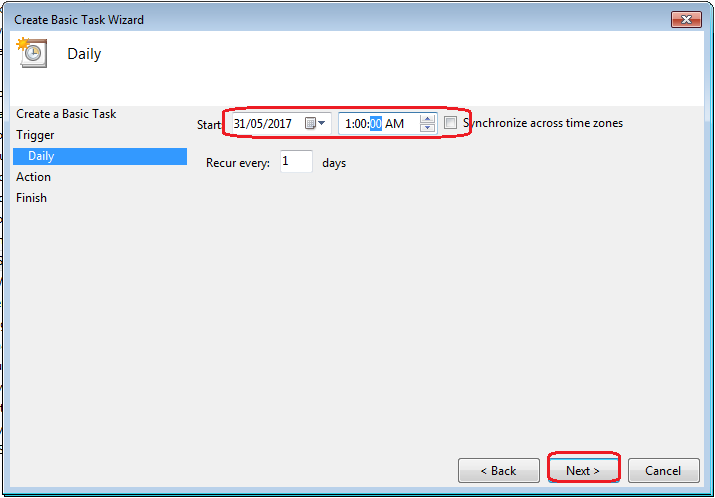
Enter what time you want to execute the task:
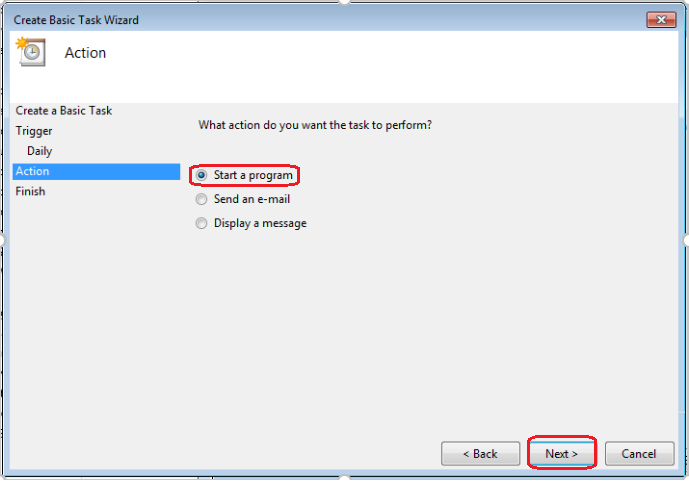
Select "Start a program":
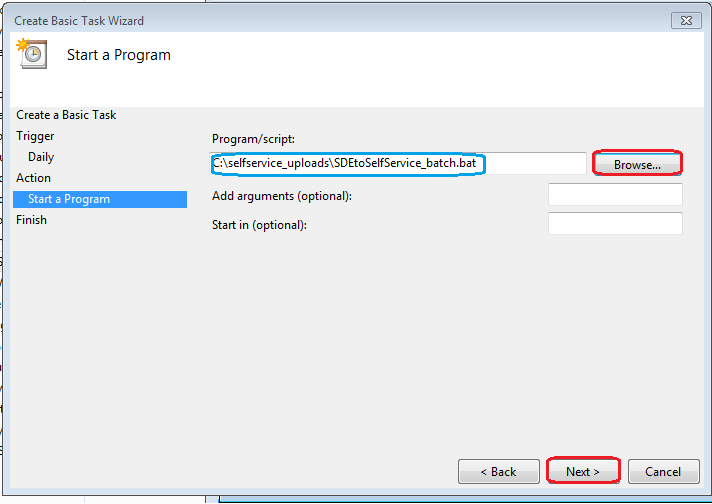
Navigate to your batch file:
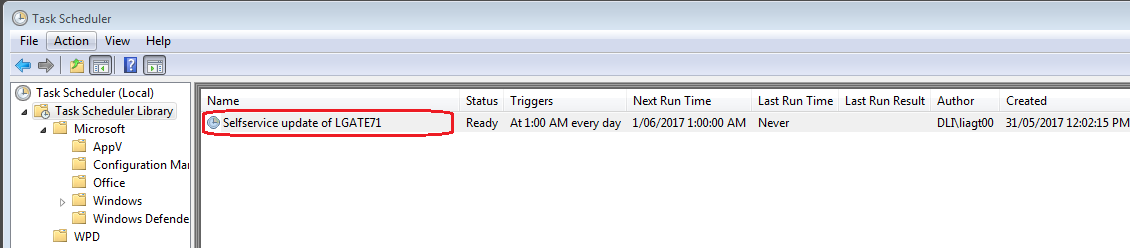
Your newly created task will now be shown in the task scheduler library:
Right click on your task and select properties:
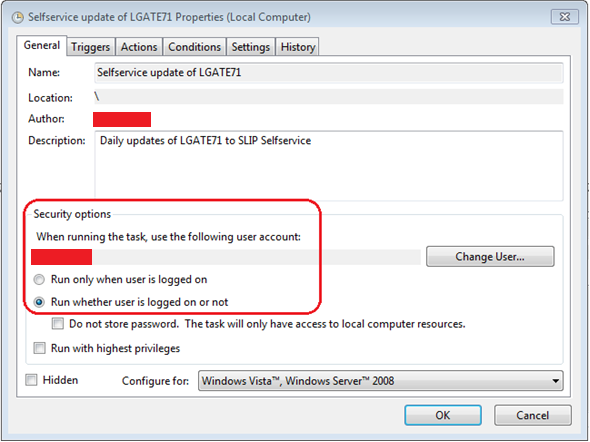
Configure the security options. Note if your account password expires the task will not execute. It is recommended to use a service account that’s password never expires.
Need more help?
arcpy help documentation: (http://pro.arcgis.com/en/pro-app/arcpy/get-started/what-is-arcpy-.htm)
Python documentation: (https://www.python.org/)
boto3 documentation: (https://boto3.readthedocs.io/en/latest/)
Custom install FME Python packages: https://docs.safe.com/fme/html/FME_Desktop_Documentation/FME_Workbench/Workbench/Installing-Python-Packages.htm