
DUT Application Version 2.8
Info: The dataset application you create in this step is the first step in the data management lifecycle and is known as the Draft phase. You will return to this state when you apply to make changes to your dataset.
![]()
This article will step through creating a new dataset application in the geospatial Data Upload Tool (DUT). This is a key step in the process of publishing your data. You’ll provide important information about your dataset, including the structure (or data schema), and how it should be styled.
Tip: Have you run through the New dataset application checklist yet? Until you’re familiar with the process of supplying data through DUT, it pays to double check that everything is in order. It will save you time down the track.
How long will this take?
Time: Completing the steps in this article will take about 30 minutes for an average dataset. 30 minutes is the estimate only if you’ve completed the preparation steps and checklists outlined in the first article in this series, High-level overview.
Prerequisites
Before your new dataset application is created in DUT, there are a few key prerequisites that need to be completed first:
- Apply for data publishing permissions. Once you’ve been approved, please read the Getting set up as a geospatial data publisher article and create the necessary system accounts.
- Create a new metadata record (or update your existing record) on the data.wa.gov.au catalogue by reading and completing the steps in the Creating your DataWA metadata record.
Important: In creating your dataset application you’ll be asked to agree to the SLIP Custodian Terms and Conditions. Before continuing, please make sure that you have the authority to agree to this on behalf of your organisation.
New dataset application walkthrough
Tip: Soon you will be asked to choose a license for your dataset that will govern how users of your data are able to reuse it. If you haven’t already decided how your data will be licensed, please refer to the first article in this series, High-level overview for more detailed guidance.
- Login to the SLIP Self Service Data Upload Tool (DUT)
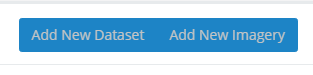
- Select your organisation and you will be taken to the Applications page
- Click “Add New Dataset” or "Add New Imagery" in the Add New, Change and Retire Datasets section to open a draft new dataset application and begin creating your record
Metadata
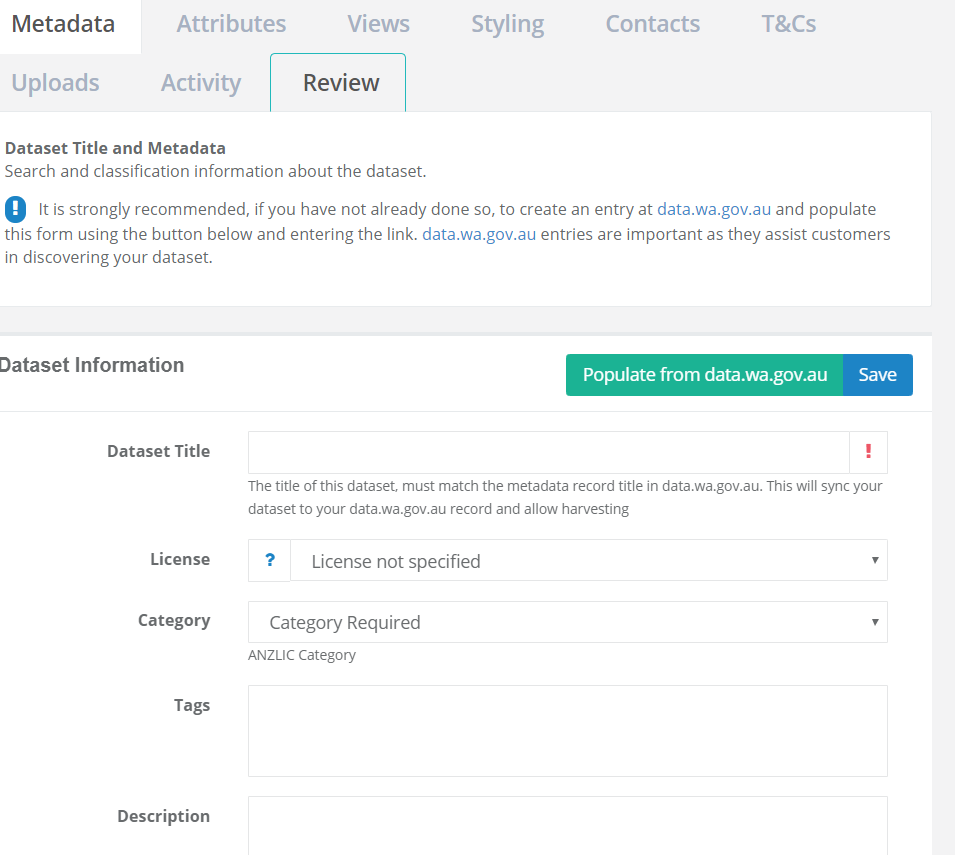
On this first tab, you’ll be asked to supply core metadata about your dataset.
Since you have already created your metadata record in the data.wa.gov.au catalogue, you can choose the “Populate from data.wa.gov.au” option. This will automatically fill in your application with information already provided in your metadata record.
Info: Choosing to populate from data.wa.gov.au ensures that metadata is not unnecessarily duplicated and will save time later. It’s also an easy way for your agency to adhere to the Western Australian Government Open Data Policy.
Populating metadata from data.wa.gov.au
- Click the “Populate from data.wa.gov.au” button:

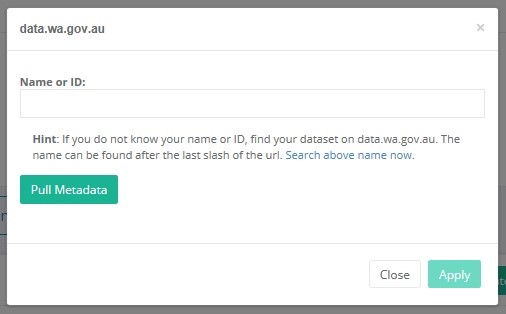
- Click the “Search above name now” link in blue text, which will open a new page to data.wa.gov.au:
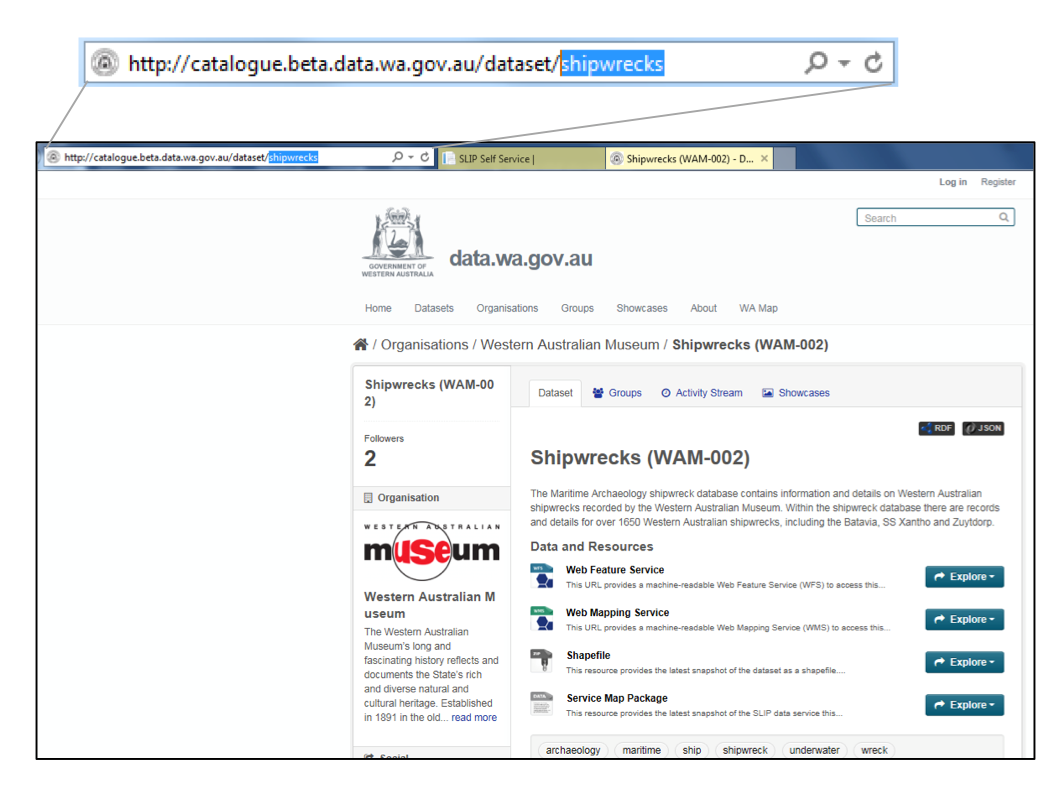
- Search for your dataset and copy the dataset name after the last slash in the URL:
- Navigate back to DUT and paste the dataset name into the “Name or ID” field and click the “Pull Metadata” button:
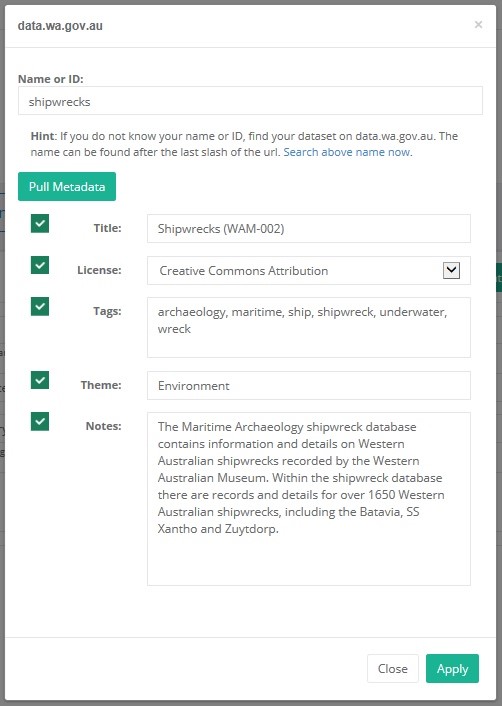
- Click ‘Apply’ and the metadata fields will automatically populate.
- Please review the metadata fields and fill in the Category field.
- Lastly, be sure to click “Save” to save your progress.
Important: It’s crucial that the title that you provide for your dataset in DUT and in data.wa.gov.au’s data catalogue match exactly. Your dataset’s title is the key that is used to automatically connect the data snapshots and services published through DUT with the data catalogue.
Licensing
When you published your metadata record to data.wa.gov.au (instructions are in the previous article) you would have selected a license for your dataset. This license governs how users of your data can reuse it.
Tip: Please double check that the system has brought across the specific license that you nominated in the data catalogue.
Reference: Please refer to the first article in this series, High-level overview for more detailed guidance around licensing.
A word on dataset identifiers
If you are familiar with publishing geospatial data through the old SLIP systems, then you’ll have encountered dataset identifiers in the past. Dataset identifiers are short exclusive codes that uniquely identify a dataset, e.g. LGATE-005 or DOP-002.
For now, you don’t need to worry about these. During the Application review process, a new dataset identifier will be assigned to your dataset. The title of your dataset with its new identifier will be updated in both DUT and in data.wa.gov.au’s data catalogue.
Reference: For more information about dataset identifiers please refer to the Dataset identifiers explained article.
Dataset Attributes
Next, you need to provide information about the structure of the data, i.e. its data schema and attributes. This information can be manually filled, or you can simply upload your data and DUT will automatically populate the attribute table. This schema and attribute information is not required for imagery datasets.
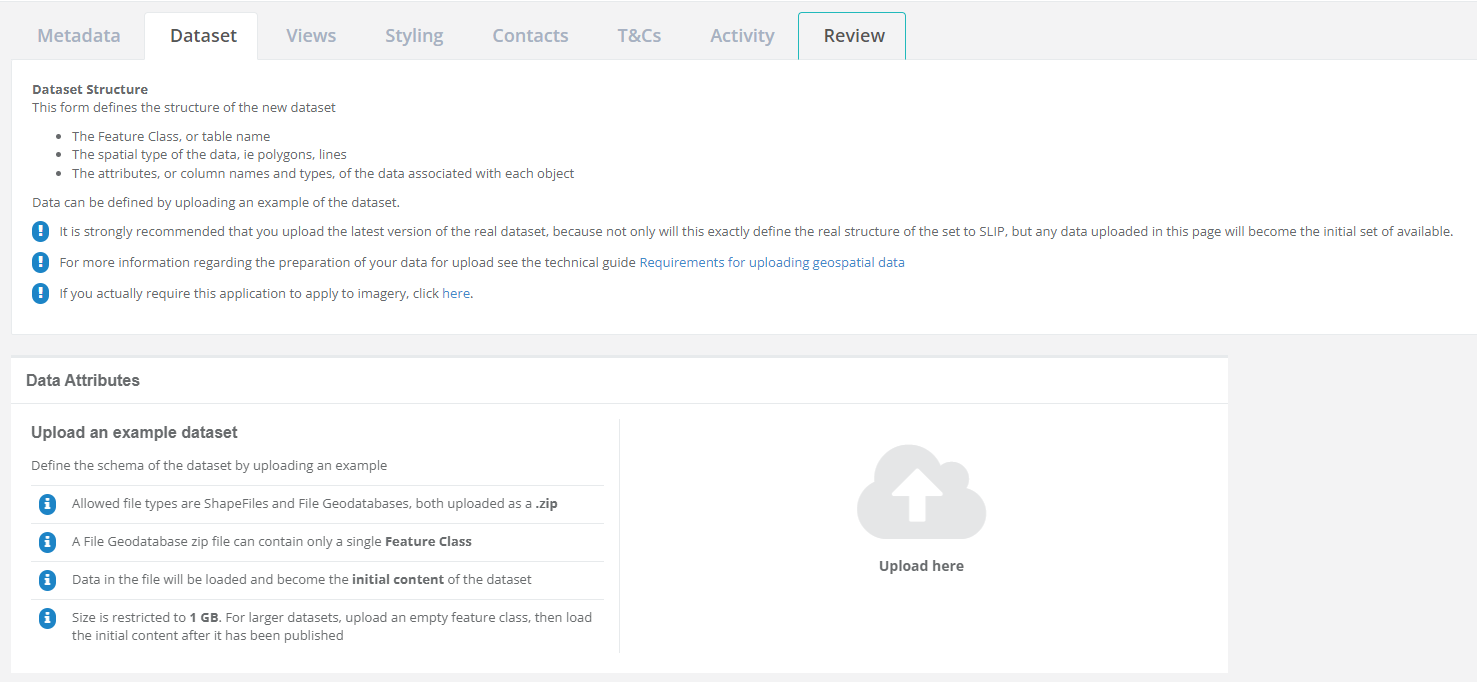
Uploading a dataset
To populate attribute information upload your dataset to DUT. Not only will this automatically fill in your attribute information, but in the next step, Application review it will also:
- test your dataset for validity, and apply the geometry repair routines,
- automatically load your data into the data store for the first time.
For most datasets – those below 2GB in size –simply drag and drop the zipped dataset directly into DUT to begin uploading it.
For imagery datasets, if the zipped file is less than 1gb then you can load via DUT. For imagery over 1gb this can be loaded directly to the S3 bucket using the credentials on the Imagery tab in the application.
Tip: At this stage you do not need to load all records in your dataset we just require the Dataset Structure. Size is restricted so for larger datasets, upload an empty feature class, then load the initial content after it has been published.
Reference: Please refer to the article Requirements for uploading geospatial data for detailed information about the data formats that are supported, and the requirements your data will need to meet to be successfully loaded into DUT.
Info: Before you upload your data, it needs to be zipped into a single file. There are a few technical gotchas here, so please refer to the Zipping your data for uploading section of the article on Scheduling data updates.
To upload your dataset to DUT:
- Click the “Upload here” button with the cloud icon. This will open a pop-up window.
- Drag and drop your zipped dataset into the pop-up window, or click the pop-up box to browse to the file to upload.
- Click “Upload” to begin the upload process.
Time: Depending on the size of your dataset and internet connection speed and reliability, this process may take some time. Please leave the browser open, and avoid refreshing the page, until the upload process is complete.
Once the upload has completed, the application will populate the Attribute Table, Feature Class Name and Geometry Type fields. This will also lock the attribute table so that no further changes can be made to the attributes.
Important: Please double check that the attribute information that has populated DUT matches what is in your dataset. Pay close attention to the names and data types of each attribute.
Tip: If you realise there’s been a mistake at this point, the attribute information can be reset by clicking the “Remove” button. This will remove the uploaded dataset, clear the attribute information, and re-enable the option to upload another dataset.
Views
With the structure of your data now defined, the next step is to define how the dataset will be published and made available to the community of data users.
Reference: Please refer to the article Access Restrictions for detailed information about the access settings that can be applied to your data. Each view can have a different access setting.
Info: Every dataset needs to have at least one view configured. Setting up views lets you control:
- how your data is published (the data formats and services that will be available)
- who can access it
- which attributes are viewable in the data,
- any aliases for your attributes that should be shown instead of the raw attribute names.
Creating a view
Choose “Add New View” to start the process of creating the required view.
- Enter a name for your view. This is simply a common sense practical name and is for admin use only. Please use a descriptive term that includes the dataset name and the purpose, e.g. “Shipwrecks – Public View”.
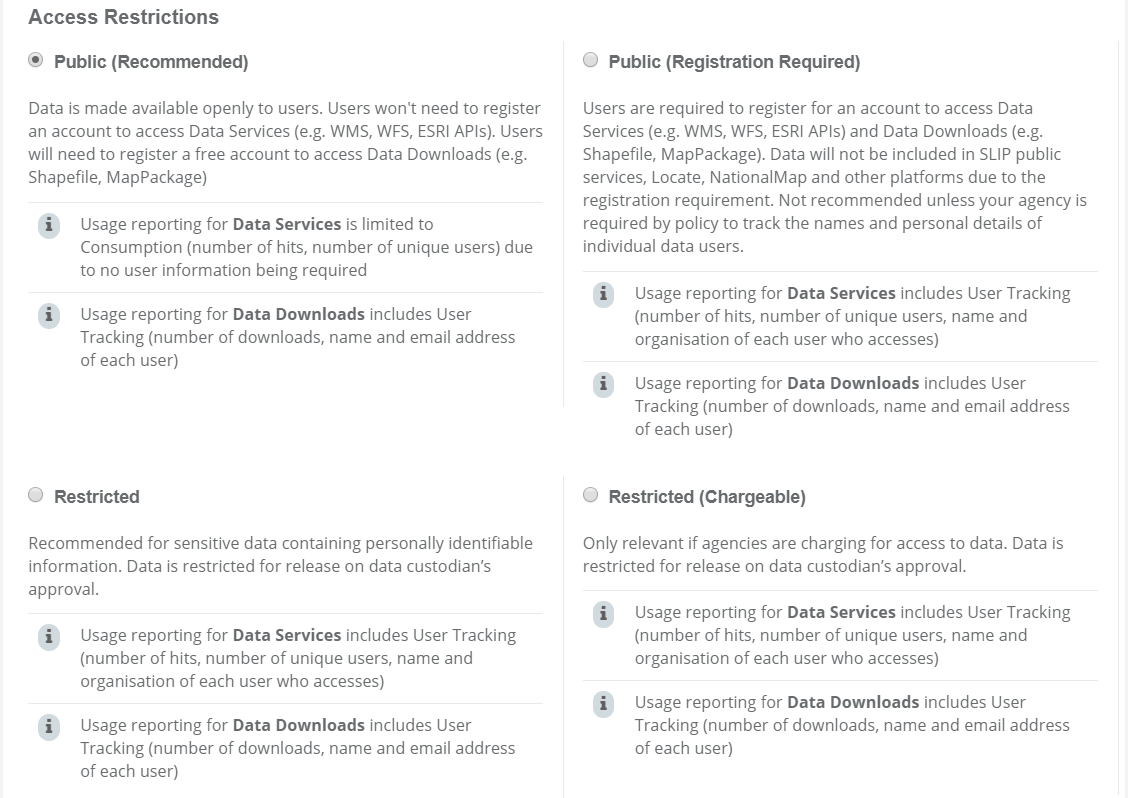
- Choose the access restriction. This controls who can access your data and how it is made available to the community of data users. For most datasets, Public is the recommended option for agencies complying with the Open Data Policy. Please refer to first article in this series, High-level overview for more information about access levels.
- Choose the services to be made available. This defines the data formats and services that will be made available. In most cases, you’ll want to check all three options to ensure that your data is available in best practice, reusable, and machine-readable formats.
- Select which attributes to include. This allows you to choose which specific attributes in your dataset should be made available in this view. In most cases simply check the displayed option for all attributes.
- Enter any aliases for your attributes. This is an optional step that lets you define aliases for some or all attributes. This is most useful for expanding attribute names into a more human readable name. e.g. You may have an attribute called coord_calc that defines how that record’s location was calculated. To make it easier to understand your data, the alias could be “Coordinate Calculation Method”.
Tip: Choosing Public, and checking all the Service options is the easiest way for your organisation to adhere to the principles of the Open Data Policy. Where there are attributes in the data that are sensitive, a second Restricted view can be published that is securely shared with other organisations and users.
Styling
Now that you’ve decided how your dataset is to be published you need to define how it should be styled and symbolised.
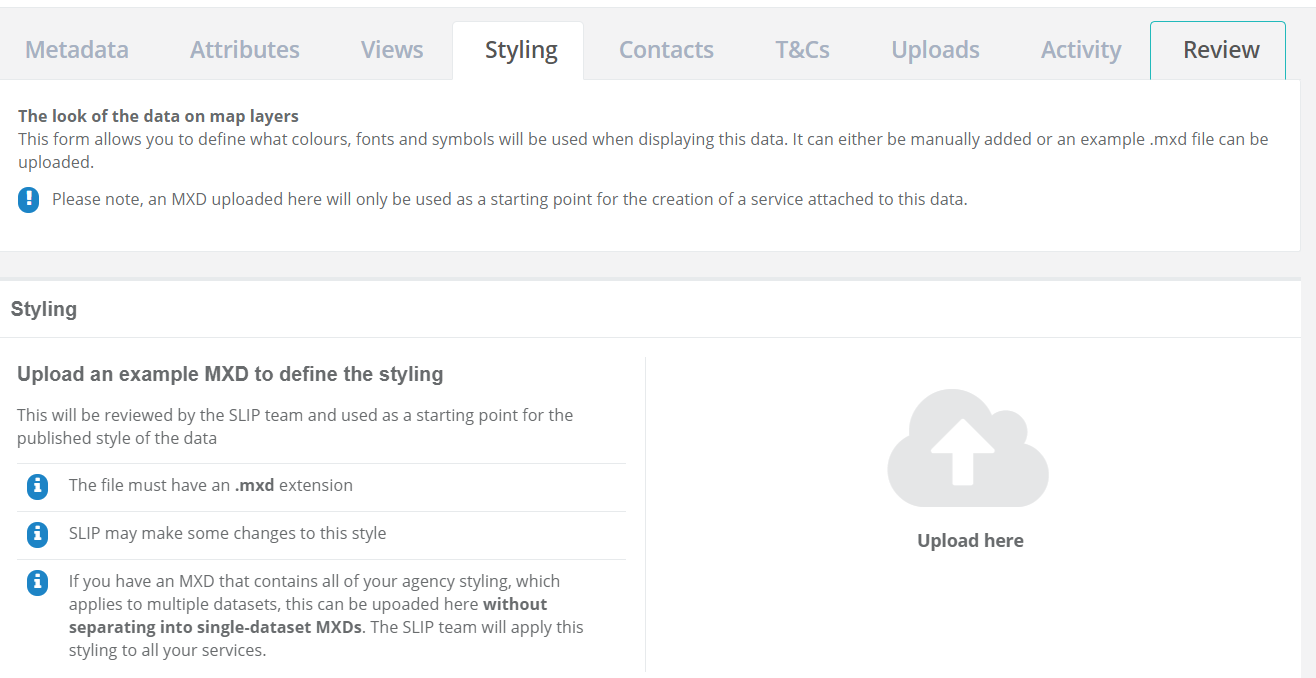
Styling information can be provided by either:
- uploading an Esri MXD file (required for complex imagery styling),
- describing the style by entering the colour, size, and labelling to be used.
Reference: Please refer to the article Preparing geospatial data symbology for detailed guidance about the symbology formats that are supported, and options for supplying symbology in formats other than MXD.
Uploading an Esri MXD (Recommended)
To upload an Esri MXD containing your dataset’s symbology:
- Click the “Upload here” icon. This will open a pop-up window.
- Drag and drop the MXD file into the pop-up window, or click the pop-up box to browse to the file.
- Click “Upload”.
Once the upload has completed the MXD file is stored alongside your dataset and it will be used to set up and publish your datasets.
Tip: Here you can supply a Corporate MXD to define how all of your datasets are styled. All other datasets can refer to this MXD.
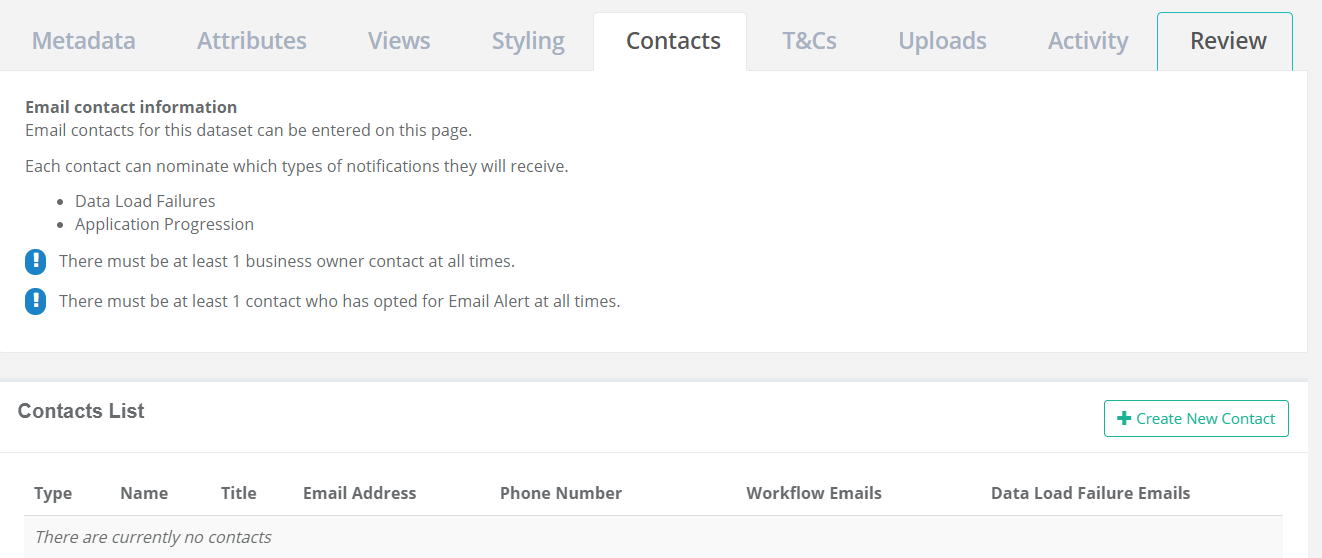
Contacts
You are almost there, just a few more steps to get through. To ensure that we know who to contact when questions or issues arise with data, each dataset must have a nominated business owner and one contact who has opted for Email Alert when a data load fails.
- Choose “Create New Contact” and provide the contact information for your business owner.
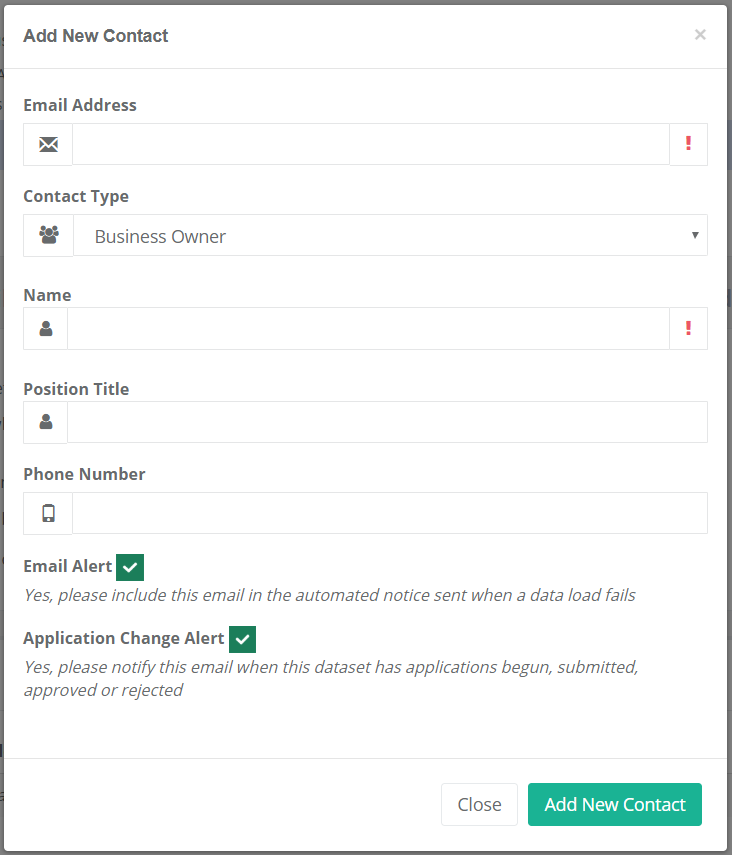
Info: The person you nominate as the business owner should be a higher-level contact within your organisation (they may be known as a data steward or data manager), and is the individual ultimately responsible and accountable for the dataset.
This contact will be used for:
- queries relating to high-level data governance issues
- approvals for access to the data (for restricted datasets),
- as a known and permanent point of contact for the data.
If the business owner is contactable on your team’s group email address, then use this contact (e.g. gis@department.wa.gov.au) as your business owner.
Providing additional contacts
In addition to the business owner contact, there are three additional types of contacts that you can also provide.
Tip: By combining notification settings with these additional contacts, a sophisticated set of rules can be created that will automatically keep everyone in your organisation appraised of changes or problems with the dataset. For example:
- Supply a Data Quality contact and check the “Email Alert” notification option so that the creator of the data will be informed of any issues with the data (recommended option).
- Supply a Group Email contact and check the “Application Change Alert” notification option so that the rest of your GIS team can be kept in the loop on any changes or notices related to the dataset.
- Supply an Other Email contact and check the “Email Alert” notification option so that the team managing your automated data uploads will receive notices when there is an issue with the upload.
Terms and Conditions
All data custodians are required to read and agree to the Custodian Terms and Conditions which set out the rights and responsibilities of Landgate (as the service provider) and you (as data custodian).
Reference: Please refer to the first article in this series, High-level overview for more detailed guidance about the agreement.
Tip: If necessary here is where you can ask your Business Owner to log in and accept the Terms and Conditions.
Public Usage Agreement
Agreeing to the Public Usage Agreement is optional and only applies to data that you are supplying for public access.
By agreeing, you are giving Landgate permission to include your data in free public maps that are produced, as well as in Landgate’s commercial product offerings. If you have any questions or concerns about the Public Usage Agreement, please don’t hesitate to get in touch.
Info: It’s important to remember that agreeing to the Public Usage Agreement does not replace the license you chose for your dataset. Nor does it apply to regular usage by any other third parties who make use of your data. They will still be bound by the terms of your chosen license.
Review and Submit
This is the last step. Please double check that you’ve provided everything needed to publish your dataset.
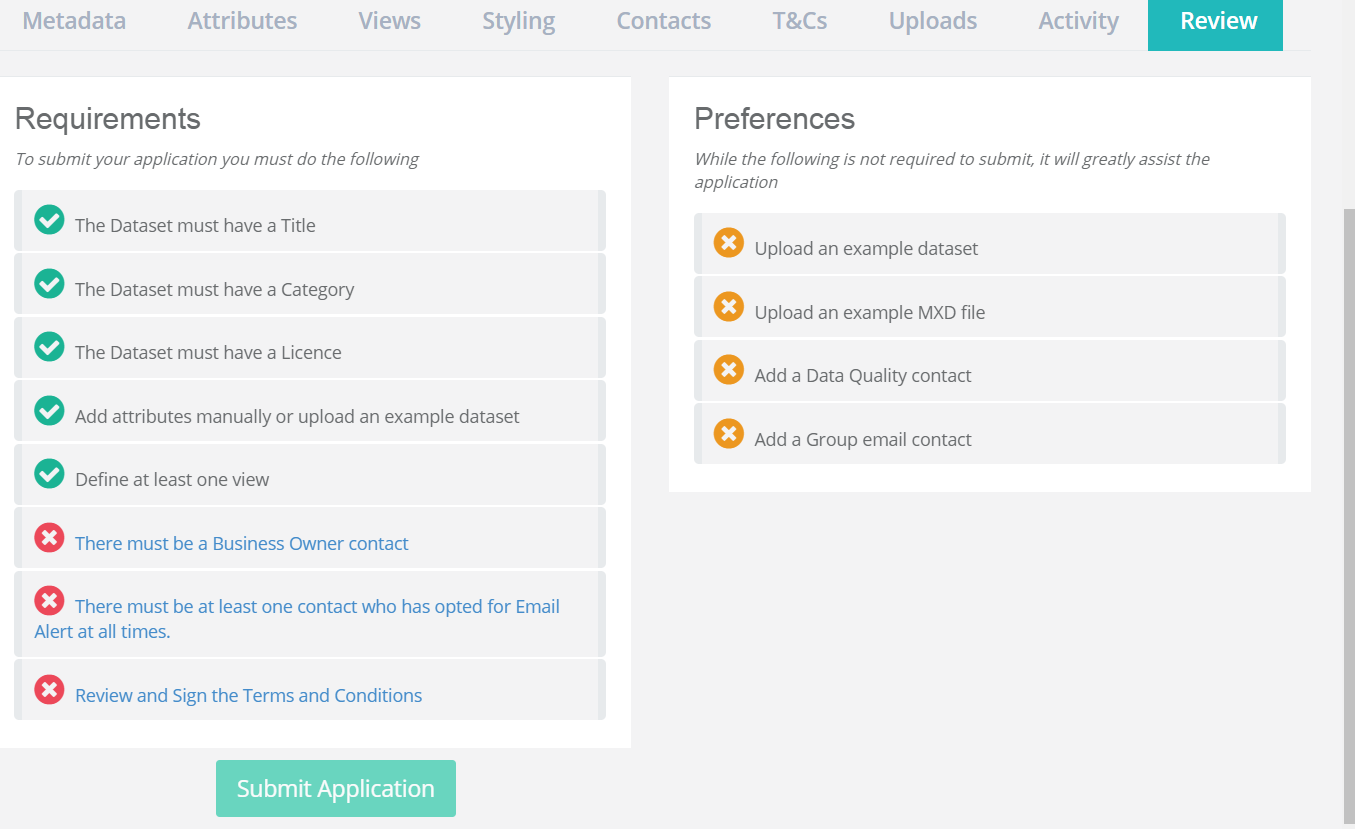
Review all tasks in the application to ensure that all compulsory information has been submitted. Red crosses will mark compulsory sections that have not been completed. Orange crosses will mark non-compulsory (but recommended) sections that have not been completed.
Once you’re happy that everything is completed and correct, it’s time to submit your application.
Can I withdraw an application?
If you pick up an error or something you’d like to change once your application is submitted (e.g. you’ve attached the wrong data), please let the team know immediately as they can reject and return the application to a draft state in the next phase.
What happens next
With your application submitted, the SLIP team will review it, check that everything is in order, and approve it for publishing. The next article in this series, Application review will cover what’s involved in that process, how long it should take, and what you can do to prepare for the remaining steps in the meantime (such as scheduling data updates).